I attended QConLondon 2013 last week; what I took from the first four sessions in the Building for Clouds track was: cloud API and infrastructure automation tools have now solved most of the ‘easy’ cloud problems, but harder challenges (such as automating clusters) remain. The sessions were from Tim Savage (@timjsavage) and Zenon Hannick (@zenonhannick) on Comic Relief’s unique challenges with performance testing, Gareth Rushgrove (@garethr) on how to avoid PaaS lock-in, Stephen Nelson-Smith (@LordCope) on how to use Chef to give you ‘optionality’ with different cloud vendors, and Andrew Crump (@acrmp) and Chris Hedley (@ChristHedley) on the CloudFoundry cloud platform.
Comic Relief – testing for a single, yearly event
Comic Relief is a UK charity which holds an annual fundraising event called Red Nose Day (the first event was set up by comedians wearing clown red noses). In 2011, over £108,000 ($160,000) was raised in a 24-hour period via telephone and online donations; that’s a big pile of cash. As more and more folks use mobile devices and apps for transactions (instead of telephone) the engineering team at Comic Relief needed to be absolutely sure that their once-in-a-year platform will hold up to the flood of donations.
Red Nose Day 2013 is not until 15th March (two weeks from the date of the QCon session), so the talk was focused on what was expected to happen rather than what happened on the night, but Tim Savage and Zenon Haddick gave a clear account of how they had designed and built the system, and how they had approached performance testing in particular.
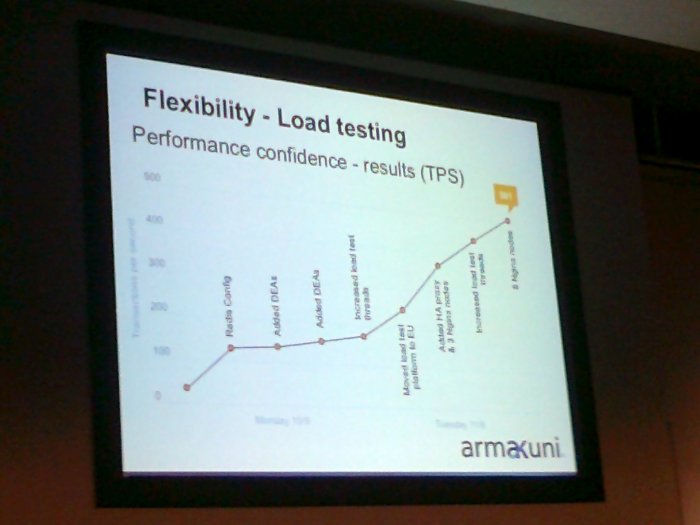
In terms of performance testing tools, they use Opscode Chef to deploy Grinder; it was good to hear of infrastructure automation tooling being used for deployments, rather than ‘just server configuration’ (as if that’s somehow different). Tim and Zenon also spoke about having ‘failure wagons’ standing by to step in when components fail (i.e. deliberately pre-provisioning extra capacity, rather than provisioning on-demand). They use script-configured round-robin DNS with low TTL as a simple but effective load distribution scheme which does not need additional services.
In order to achieve the resilience and throughput required, the Red Nose Day system uses:
- Message queues
- Stateless requests
- Eventual consistency (i.e. sacrificing the C of CAP)
Particularly interesting was that Tim and Zenon felt that:
third-party service commoditisation has allowed Comic Relief to stay in control of risk
Many organisations view third-party commodity (‘cloud’) services as being more risky than internal services, but Comic Relief clearly have some smart people on board to be able to understand the risk profile in this way.
For me, one of the really interesting things about an organisation such as Comic Relief with a naturally long release cycle is how this fits with practices such as Continuous Delivery, which holds that shorter release cycles tend to improve the product, reduce risk, and reduce the test burden. I spoke to Zenon after the session to see how things had progressed since we last spoke at XPDay 2012 in terms of Continuous Delivery, and some interesting insights emerged: the secret is to find more regular release points, even if these are just to an internal or Pre-Production system, and get buy-in from the right levels to help drive these shorter cycles. I suspect that this aspect of Continuous Delivery (“achieve a shorter release cycle, even if it’s not possible to get to Production“) would make for an interesting session at the London Continuous Delivery meetup group.
Gareth Rushgrove on avoiding PaaS lock-in
Gareth Rushgrove curates the excellent DevOpsWeekly newsletter and currently works for the Government Digital Service (GDS), the new in-sourced ‘crack team’ of software systems engineers transforming government services in the UK. One of the crucial aspects of the work which GDS needs to do is to change how IT services are commissioned, from the old-school “single massive supplier” model to a more lean “right size in each case” approach. In this context, Gareth shared some experience of the potential pitfalls of commissioning cloud services.

Gareth took us through his “Five Perils of Cloud Portability”; in increasing order of importance, these were:
- Caring too much about VM image formats (.vmdk, .ovf, etc.) – convert between them and move on.
- Caring too much about the size of APIs across different suppliers (Amazon AWS has over 1000 possible operations in its API) – focus on just what you need, not more.
- Caring too much about being able to translate cloud primitives (such as auto-scaling, provisioning, etc.) between the APIs of different cloud platforms (fog.io, libcloud, jcloud, etc.) – cloud technology is too young for abstractions to have become stable.
- The ‘slippery slope of PaaS’ – where you start off using IaaS features of the cloud provider (such as VM provisioning, environment cloning, etc.), but accidentally start to use vendor-specific features, such as special data stores or DNS management.
- Vendor lock-in – there are several kinds of lock-in:
- Capability lock-in: Elastic Beanstalk from AWS is a feature which cannot be found elsewhere
- Capacity lock-in: where the volume of your data is so large that no other provider would be able to provide the service (e.g. Netflix)
- Ecosystem lock-in: where there might be multiple suppliers but they ‘all look the same’ (e.g. IBM, HP, FujitsuSiemens) and there is little competition or innovation.
In summary, Gareth advised us to
focus on capabilities rather than a standard API
and look to bridge differences in vendor APIs by writing your own code.
Stephen Nelson-Smith on using Chef to provide ‘optionality’ for cloud providers
The book Test-Driven Infrastructure with Chef by Stephen Nelson-Smith is only 18 months old, yet is already a classic in the infrastructure automation space and a must-read for anyone using Chef; I’m also looking forward to Stephen’s forthcoming new book Chef: the Definitive Guide.
Stephen showed how we can use Chef (Puppet or CFEngine would also work) in order to give ourselves ‘optionality’ when it comes to cloud providers.

Because Chef recipes can be written in such a way to as to abstract the underlying implementation away from most of the code (technically, via Resources and particularly LWRPs), using Chef we can retain the option to move to a different cloud provider without having to rewrite more than a small proportion of our infrastructure code. The concept of “convergence” is a useful one for infrastructure, where we speak of ‘converging’ the infrastructure towards the policy defined in Chef code.
The code in the slides was pithy and easy to read, and Stephen gave useful pointers to Ironfan, a Chef orchestration layer, and the fact that Vagrant 1.1 will soon be able to target many different virtualisation technologies (AWS, RackSpace, etc.), not just VirtualBox (which has been a limitation until now).
Andrew Crump and Chris Hedley on CloudFoundry
Andrew Crump and Chris Hedley talked in detail about the capabilities of the cloud platform CloudFoundry, including a demo of how to provision and configure servers via the CloudStack API (wisely pre-recorded, given the abysmal WiFi in the venue).

It was good to hear that CloudFoundry will soon add a concept called Organization, which appears to map closely to Chef’s Organization, allowing for multiple business entities to be modelled in the same account.
The tooling around CloudFoundry mentioned by Andrew and Chris included:
- Yeti – for end-to-end testing
- Stac2 – for load testing
- bosh – for deployments (fairly involved)
- Chef – deployments and infrastructure
One thing I found slightly surprising was that CloudFoundry needs to know about particular bits of software before you can use them; so if a new version of MySQL comes out, the CloudFoundry team must first add that new version to their inventory and update the CloudFoundry code in order to make it available for use. This distinguishes CloudFoundry from alternatives such as Cloudify, which will deploy any version of any application. That said, the spirit of CloudFoundry is spot on; Andrew and Chris made it clear that:
Your PaaS should be hackable [programmable]
This is the Infrastructure-as-Code ideal. Interestingly, the more complicated configurations – such as those for HA clustering or failover – are not yet available in CloudFoundry (although these are being worked on); this reflected discussions throughout the day in other sessions.
Cloud tools now need to tackle tricky HA and clustering problems
A common thread through the four sessions was that infrastructure automation and cloud management tooling is now sufficiently advanced to cover practically all the basic automation cases (single servers, scaling, provisioning, DNS re-configuration, etc.), but that the more difficult problems have yet to be tackled: setting up a MySQL Master-Slave pair, or a clustered server group for HA. I think that 2013 is going to be an interesting year in the cloud/infrastructure tooling space!
