Alex Papadimoulis (@apapadimoulis) of Inedo (and TheDailyWTF) gave a really useful talk on deployments for cloud-based software systems at QConLondon 2013 recently [slides, PDF, 1.6MB].
He stressed the importance of finding the appropriate deployment (distribution + delivery) model for each application, and to keep deployments as simple as possible. In fact, we can follow the best practices from Continuous Integration and apply them to deployment.
Continuous Deployment is not for everyone
We heard about deployments at social interaction site imvu (“the world’s largest 3D Chat and Dress-Up community”), where every code commit is automatically deployed directly to Production (after a suite of automated tests). Alex pointed out that this is not the best pattern for most organisations: imvu’s users apparently do not care too much about glitches on the website caused by too-keen deployments, presumably due to the user demographic (mostly teenagers?) and the lack of a pay-for product being sold.
Enterprises tend to want to minimise the risk of change, and that’s where having some up-to-date deployment practices can help hugely.

Deployment Fundamentals
Alex reviewed some enterprise-y deployment fundamentals which help to minimise the risk of change, such as:
- the importance of a single artifact repository
- every deployment should be Reliable, Repeatable, Rapid [and Recurring]
- only deploy what has changed (break the monolith)
- use semantic versioning to capture dependencies
- every build is a candidate release
It’s clear to me from this list that we’re at the same stage in 2013 with deployments that we were 10 years ago in 2003 with source code, when the Continuous Integration argued for:
- a single source code repository
- every build should be Reliable, Repeatable, Rapid, and Recurring
- only build what has changed
- use version control to manage dependencies
- every commit is a candidate build
That is, large, big-bang, platform-style deployments are typically more risky than deploying a series of smaller, incremental, easily testable and fixable changes.
Simplifying Deployment
Alex sees Deployment as two distinct steps:
- Distribution – analogous to a retailer taking stock from their warehouse (think: artifact repository) and handing it to a delivery company (DHL, ParcelForce, FedEx, etc.) to deliver to an address (think: file location on a server)
- Delivery – analogous to the delivery company completing the shipment by taking the parcel (think: deployment package) to the final destination address
Splitting out deployment into Distribution and Delivery like this helps to simplify the problem space and keep the implementations of deployment from being over-engineered.
Also useful is the concept of a ‘Promotion’ step prior to deployment: a package is promoted to a particular environment to make it available for deployment. Again, this separation of concerns helps us to identify distinct responsibilities and implement simpler solutions accordingly.
In fact, Alex argued that had Twitter used a simple deployment setup (consisting of a ‘staging’ directory on the server, only delivering changed files (by using a diff), and placing static assets on CDNs), then:
the Twitter engineering team would not have had to build their impressive but over-engineered BitTorrent-based deployment system.
Whether Twitter had additional problems which really required BitTorrent, we don’t know, but the important point from Alex was that deployment schemes should as simple as possible.
Deployment Delivery Mechanisms
According to Alex, most enterprises use a ‘push’ deployment model, where files are pushed from a controlling server. Rarely is ‘pull’ used, where delivery is initiated from the target machines by pulling from a central store.
Two key things to consider during deployment delivery are:
- Orchestration: ordering of actions; volumes of network traffic; etc.
- Monitoring: failed deployments; slow deployments; etc.
In particular, Alex argued that monitoring with tools such as Chef, Puppet, and CFEngine is difficult, and recommended that you:
limit [the use of] Chef & Puppet to infrastructure changes, not software
I’m not sure I agree completely with this, but it’s certainly good cautionary advice.
Roll-out Strategies
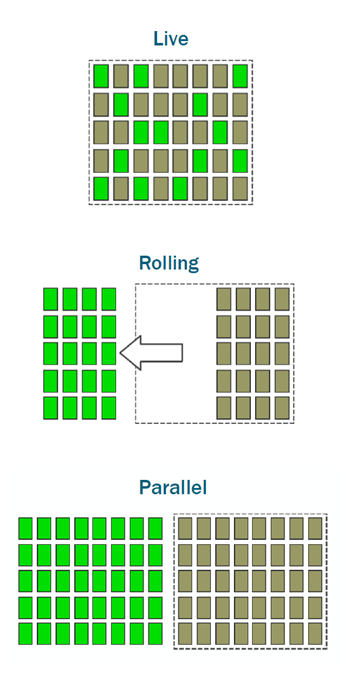
Alex characterised three different roll-out schemes. In order of increasing hardware cost, these are:
- Live: pick a subset of servers currently in load, and roll out new code to them directly
- Rolling: take a subset of servers out of load, roll out new code, then add back into load, and ‘rinse and repeat’ with the remaining servers
- Parallel: use a ‘blue-green deployment‘ model, where the production slice is duplicated, and you switch between the ‘blue’ slice being under load, and the ‘green’ slice being under load
The slide deck has more detail:
Alex stressed the importance of keeping different release workflows for different applications. Do not try to find a ‘one-size-fits-all’ release scheme, because different applications need different steps; more testing, more complicated database changes, simpler server set-up, fewer machines, etc.
Wrap-up
Cloud systems allow us to make mistakes more cheaply with deployment, as we can experiment with server release groups and other configurations more easily than with traditional (physical or on-premise) servers.
For me, the key messages from Alex’s talk were: every change to Production is simply another deployment – there is nothing special about a ‘Release’; find the right deployment scheme for each application, and do not look for a single scheme for all your apps; keep deployments simple.
