Update (2022): my company Conflux now offers consulting and training around DevOps topologies and related practices like Team Topologies.
Update (2019): I have co-authored a book – Team Topologies – that adds brand new material to these (original) DevOps Topologies patterns. In the book we cover dynamic organization evolution, team interaction patterns, the strategic use of Conway’s Law, monolith decomposition, and many more topics.
See teamtopologies.com and follow us on Twitter at @TeamTopologies for updates. The book is published by IT Revolution Press (Sept 2019).

Matthew Skelton and Manuel Pais
IT Revolution Press, Sept 2019
Update (2016): A new version of these DevOps team topologies is now here: devopstopologies.com

The new version has many new topologies that we’ve encountered in the wild and we’re taking pull requests on Github for additions and changes.
The primary goal of any DevOps setup within an organisation is to improve the delivery of value for customers and the business, not in itself to reduce costs, increase automation, or drive everything from configuration management; this means that different organisations might need different team structures in order for effective Dev and Ops collaboration to take place.

So what team structure is right for DevOps to flourish? Clearly, there is no magic conformation or team topology which will suit every organisation. However, it is useful to characterise a small number of different models for team structures, some of which suit certain organisations better than others. By exploring the strengths and weaknesses of these team structures (or ‘topologies’), we can identify the team structure which might work best for DevOps practices in our own organisations, taking into account Conway’s Law.
A new version of these DevOps team topologies is now here: devopstopologies.com
The new version has many new topologies that we’ve encountered in the wild and we’re taking pull requests on Github for additions and changes.
Most of these DevOps topologies have been described elsewhere before; in particular, Lawrence Sweeney of CollabNet goes into useful detail in a comment on Ben Kepes’s blog about what I characterise here as Anti-Type B (DevOps Silo), Type 3 (IaaS), and Type 1 (Smooth Integration). The DevOpsGuys have a list of Twelve DevOps Anti-Patterns, and Jez Humble, Gene Kim, Damon Edwards (and many others) have said similar things. I have added here three additional ‘topologies’ which I’ve not seen or heard discussed much (Fully Embedded, DevOps-as-a-Service, and Temporary DevOps Team).
DevOps Anti-Types
First of all, it’s useful to look at some bad practices, what we might call ‘anti-types’ (after the ubiquitous ‘anti-pattern‘).
Anti-Type A: Separate Silos
This is the classic ‘throw it over the wall’ split between Dev and Ops. It means that story points can be claimed early (DONE means ‘feature-complete’, but not working in Production), and software operability suffers because Devs do not have enough context for operational features and Ops folk do not have time or inclination to engage Devs in order to fix the problems before the software goes live.

We likely all know this topology is bad, but I think there are actually worse topologies; at least with Anti-Type A (Separate Silos), we know there is a problem.
Anti-Type B: Separate DevOps Silo
The DevOps Silo (Anti-Type B) typically results from a manager or exec deciding that they “need a bit of this DevOps thing” and starting a ‘DevOps team’ (probably full of people known as ‘a DevOp‘). The members of the DevOps team quickly form another silo, keeping Dev and Ops further apart than ever as they defend their corner, skills, and toolset from the ‘clueless Devs’ and ‘dinosaur Ops’ people.
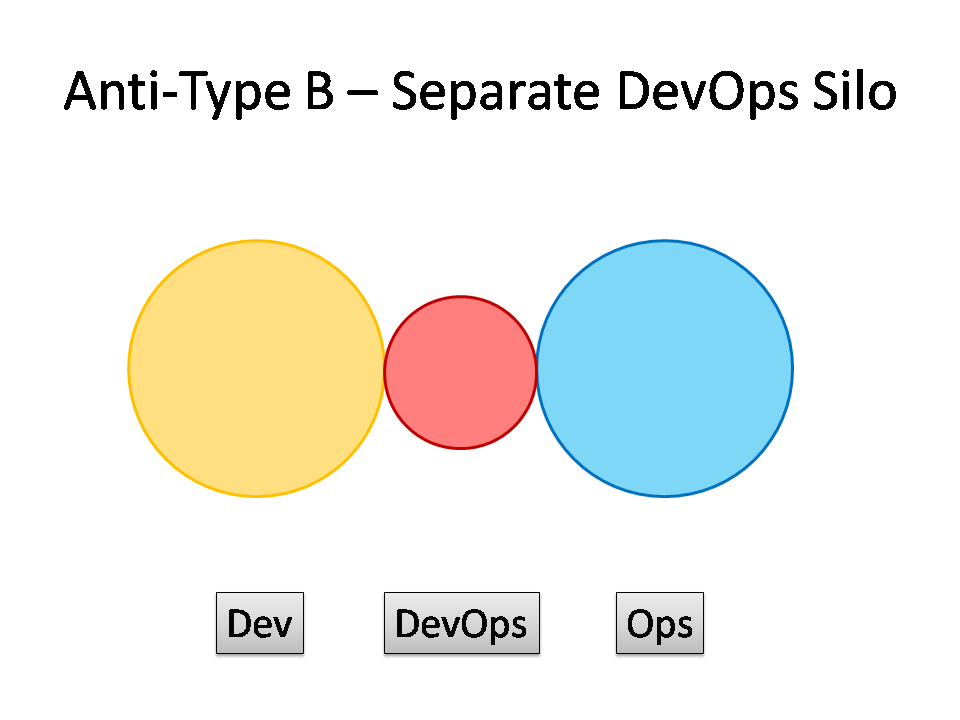
The only situation where a separate DevOps silo really makes sense is when the team is temporary, lasting less than (say) 12 or 18 months, with the express purpose of bringing Dev and Ops closer together, and with a clear mandate to make the DevOps team superfluous after that time; this becomes what I have called a Type 5 DevOps Topology (below).
Anti-Type C: “We do not need Ops”
This topology is borne of a combination of naivety and arrogance from developers and development managers, particularly when starting on new projects or systems. Assuming that Ops is now a thing of the past (“we have the Cloud now, right?”), the developers wildly underestimate the complexity and importance of operational skills and activities, and believe that they can do without them, or just cover them in spare hours.

Such an Anti-Type C DevOps topology will probably end up needing either a Type 3 (IaaS) or a Type 4 DevOps topology (DevOps-as-a-Service) when their software becomes more involved and operational activities start to swamp ‘development’ (aka coding) time. If only such teams recognised the importance of Operations as a discipline as important and valuable as software development, they would be able to avoid much pain and unnecessary (and quite basic) operational mistakes.
DevOps Team Topologies
Having seen what makes the anti-types bad, we can look at some topologies in which DevOps can be made to work.
Type 1: Smooth Collaboration
This is the ‘promised land’ of DevOps: smooth collaboration between Dev teams and Ops teams, each specialising where needed, but also sharing where needed. There are likely many separate Dev teams, each working on a separate or semi-separate product stack.
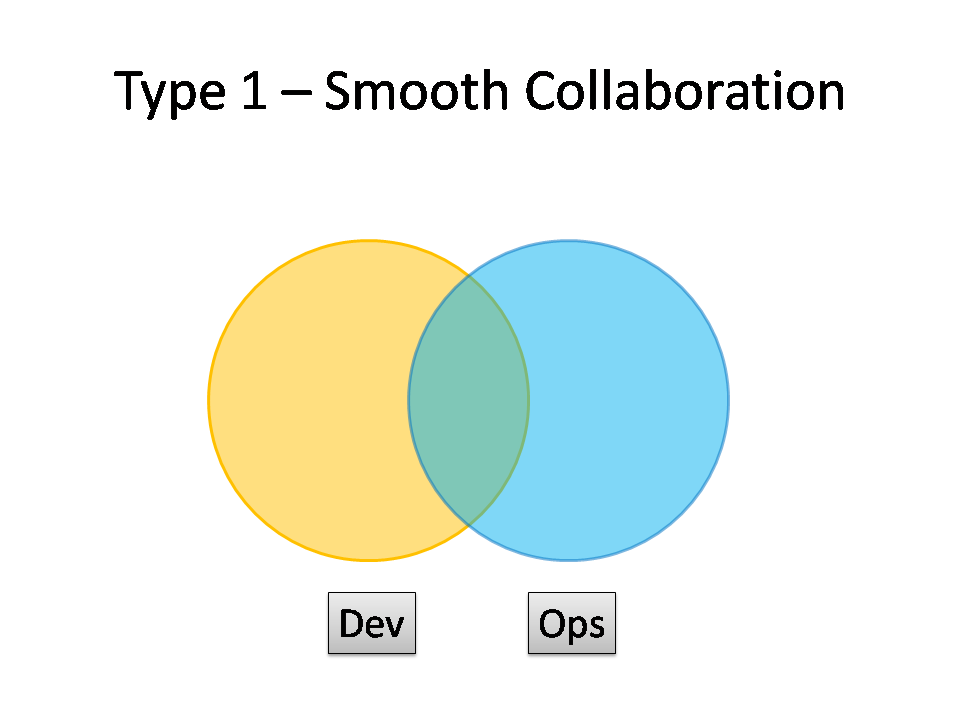
My sense is that the Type 1 Smooth Collaboration model needs quite substantial organisational change to establish it, and a good degree of competence higher up in the technical management team. Dev and Ops must have a clearly expressed and demonstrably effective shared goal (‘Delivering Reliable, Frequent Changes’, or whatever). Ops folk must be comfortable pairing with Devs and get to grips with test-driven coding and Git, and Devs must take operational features seriously and seek out Ops people for input into logging implementations, and so on, all of which needs quite a culture change from the recent past.
Type 1 suitability: an organisation with strong technical leadership.
Potential effectiveness: HIGH
Type 2: Fully Embedded
Where operations people have been fully embedded within product development teams, we see a Type 2 topology. There is so little separation between Dev and Ops that all people are highly focused on a shared purpose; this is arguable a form of Type 1, but it has some special features.
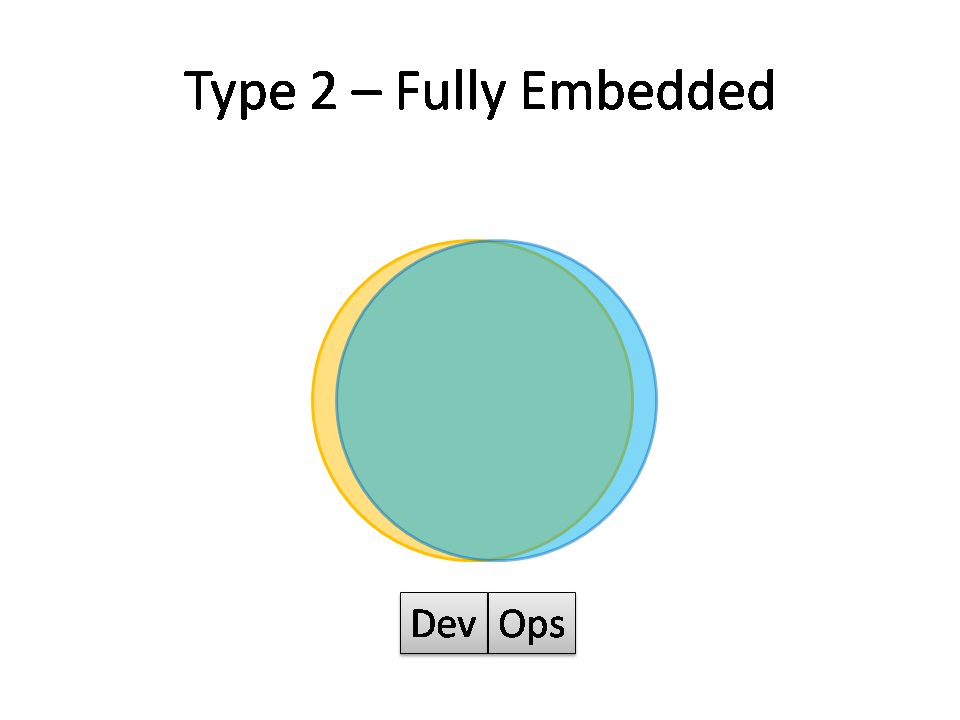
Organisations such as Netflix and Facebook with effectively a single web-based product have achieved this Type 2 Fully Embedded topology, but I think it’s probably not hugely applicable outside a narrow product focus, because the budgetary constraints and context-switching typically present in an organisation with multiple product streams will probably force Dev and Ops further apart (say, back to a Type 1 model). The Fully Embedded topology might also be called ‘NoOps‘, as there is no distinct or visible Operations team (although the Netflix NoOps might also be Type 3, IaaS).
Type 2 suitability: organisations with a single main web-based product or service.
Potential effectiveness: HIGH
Type 3: Infrastructure-as-a-Service
For organisations with a fairly traditional IT Operations department which cannot or will not change rapidly [enough], and for organisations who run all their applications in the public cloud (Amazon EC2, Rackspace, Azure, etc.), it probably helps to treat Operations as a team who simply provide the elastic infrastructure on which applications are deployed and run; the internal Ops team is thus directly equivalent to Amazon EC2, or Infrastructure-as-a-Service.
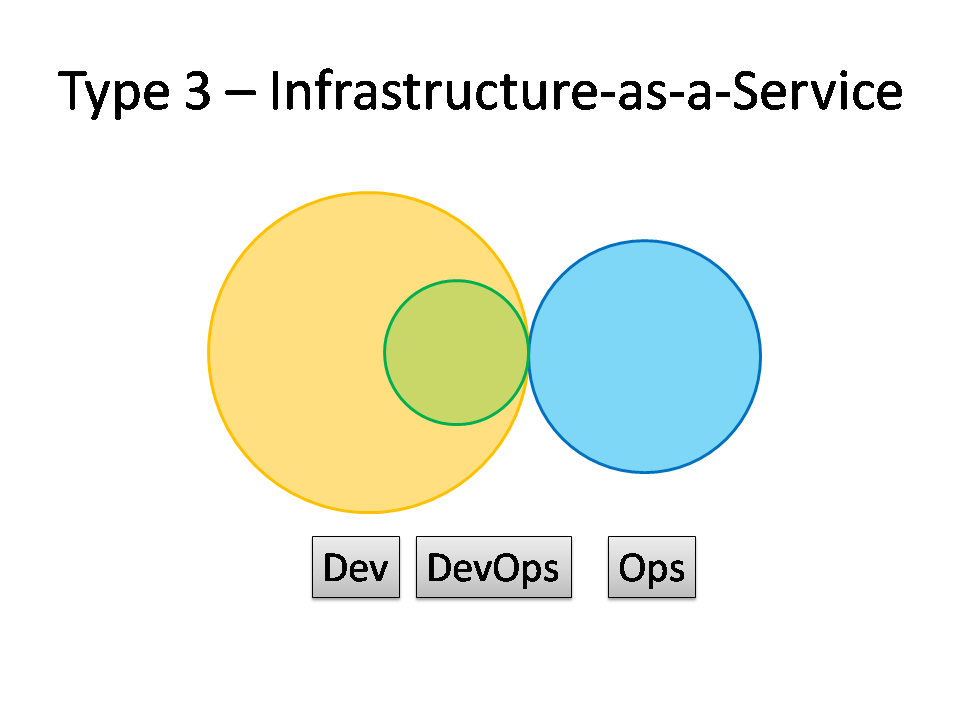
A team (perhaps a virtual team) within Dev then acts as a source of expertise about operational features, metrics, monitoring, server provisioning, etc., and probably does most of the communication with the IaaS team. This team is still a Dev team, however, following standard practices like TDD, CI, iterative development, coaching, etc.
The IaaS topology trades some potential effectiveness (losing direct collaboration with Ops people) for easier implementation, possibly deriving value more quickly than by trying for Type 1 (Smooth Collaboration) which could be attempted at a later date.
Type 3 suitability: organisations with several different products and services, with a traditional Ops department, or whose applications run entirely in the public cloud.
Potential effectiveness: MEDIUM
Type 4: DevOps-as-a-Service
Some organisations, particularly smaller ones, might not have the finances, experience, or staff to take a lead on the operational aspects of the software they produce. The Dev team might then reach out to a service provider like Rackspace to help them build test environments and automate their infrastructure and monitoring, and advise them on the kinds of operational features to implement during the software development cycles.
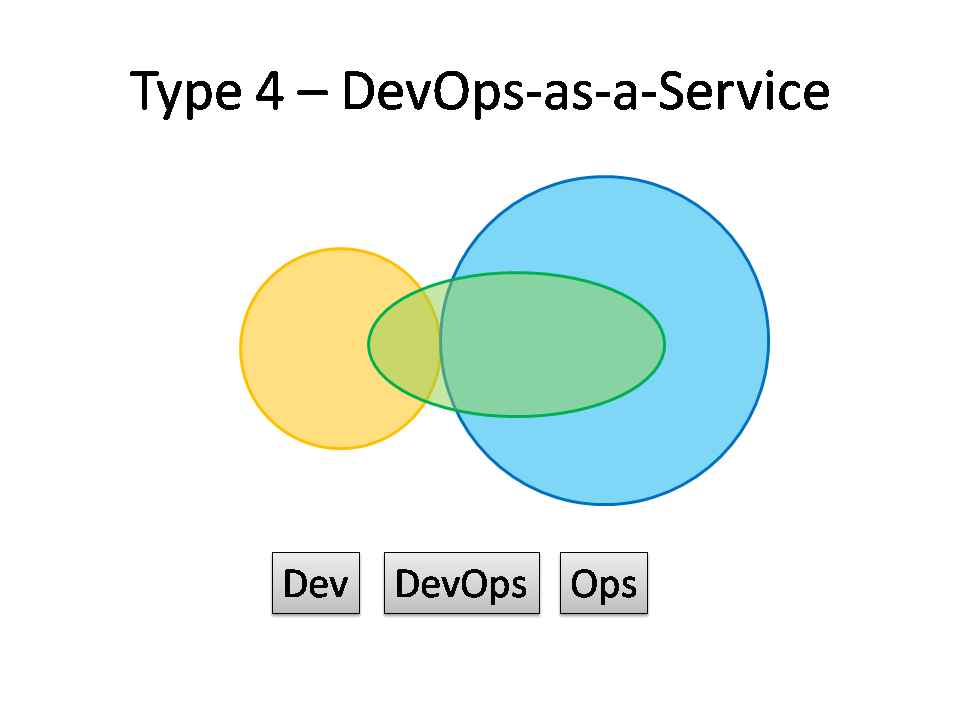
What might be called DevOps-as-a-Service could be a useful and pragmatic way for a small organisation or team to learn about automation, monitoring, and configuration management, and then perhaps move towards a Type 3 (IaaS) or even Type 1 (Smooth Collaboration) model as they grow and take on more staff with operational focus.
Type 4 suitability: smaller teams or organisations with limited experience of operational issues.
Potential effectiveness: MEDIUM
Type 5: Temporary DevOps Team
The Temporary DevOps Team (Type 5) looks substantially like Anti-Type B (DevOps Silo), but its intent and longevity are quite different. The temporary team has a mission to bring Dev and Ops closer together, ideally towards a Type 1 or Type 2 model, and eventually make itself obsolete.
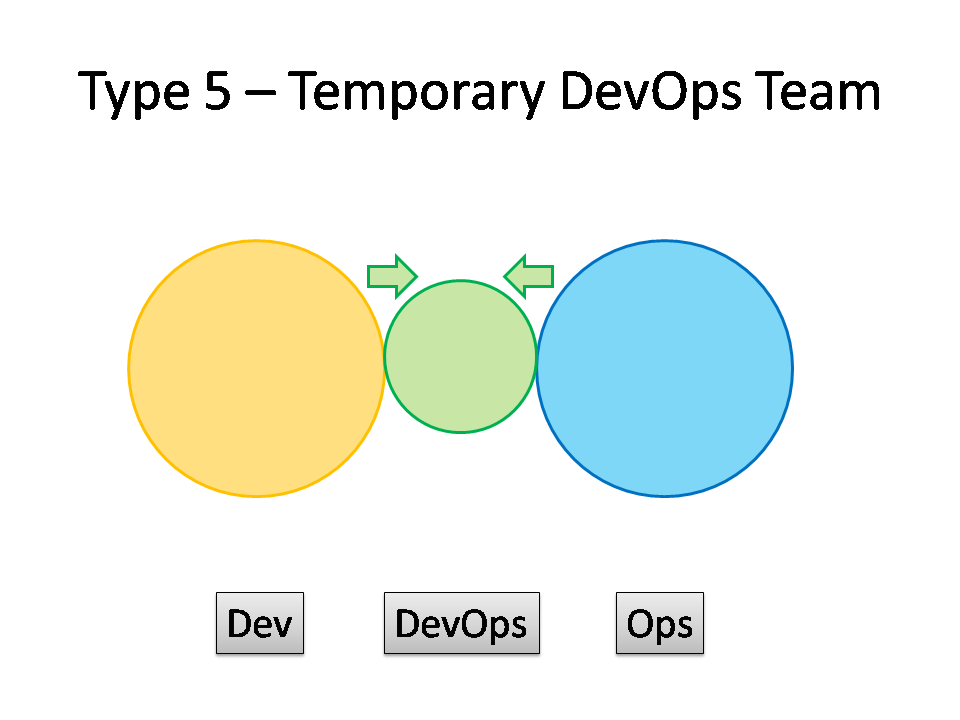
The members of the temporary team will ‘translate’ between Dev-speak and Ops-speak, introducing crazy ideas like stand-ups and Kanban for Ops teams, and thinking about dirty details like load-balancers, management NICs, and SSL offloading for Dev teams. If enough people start to see the value of bringing Dev and Ops together, then the temporary team has a real chance of achieving its aim; crucially, long-term responsibility for deployments and production diagnostics should not be given to the temporary team, otherwise it is likely to become a DevOps Silo (Anti-Type B).
Type 5 suitability: as a precursor to Type 1 topology, but beware the danger of Anti-Type B.
Potential effectiveness: LOW to HIGH
Summary
Exactly which DevOps team structure or topology will suit an organisation depends on several things:
- The product set of the organisation: fewer products make for easier collaboration, as there will be fewer natural silos, as predicted by Conway’s Law.
- The extent, strength, and effectiveness of technical leadership; whether Dev and Ops have a shared goal.
- Whether an organisation has the capability or appetite to change its IT Operations department from ‘racking hardware’ and ‘configuring servers’ to real alignment with the value stream, and for operational features to be taken seriously by software teams.
- Whether the organisation has the capacity or skills to take the lead on operational concerns.
Of course, there are variations on the themes outlined here; the topologies and types are meant as a reference guide or heuristic for assessing which patterns might be appropriate. In reality, a combination of more than one pattern, or one pattern transforming into another, will often be the best approach.
Acknowledgements
Thanks to @owainperry, @kief, @agilestevesmith, @TomAkehurst, @jamesbetteley, @johnC_bristol, and #londoncd members for helpful discussions about these ideas.

I think that Type 3 is dangerously close to an anti-type as well. Where your suitability says “traditional ops team”, this really is a description of “gnarly old unix neckbeards, who refuse to do anything other than an old version of perl”.
If the ops folk have even the slightest desire to make things better, and embrace the devops culture, rather than being the previously mentioned neckbeard stereotypes, then having a team within the dev team, essentially “doing all the cool shit”, seriously runs the risk of alienating the ops team even more, and driving a a larger wedge between the two silos.
Hi Mat, thanks for the comments.
I agree with you that Type 3 is not an ideal end-state for organisations with an internal Ops capability, but for some organisations it might be a reasonable short-term or medium term approach, particularly if the ‘Ops’ people are *really* not interested in learning Git or pairing with Devs, etc. These places do exist, sadly.
For organisations with all their stuff in ‘the cloud’, I think Type 3 works reasonably well (and there isn’t really an alternative for them). What do you think?
(See you at #infracoders 🙂 )
Matthew
Nice post Matthew. Great to see some acknowledgment that a no-size DevOps team does not fit all!
I’ve seen good results with 4 and 5 which I’ve gone into detail on here:
http://wp.me/p3EQlU-3N
Hi Markos. Thanks for the comments and link. Clearly, avoiding yet another silo is the key thing.
This is a really useful post. Team structure is a really hot topic for us at the moment, and I think we’ve been lacking a framework on which to hang the discussion, so this will definitely help. One of my ops colleagues independently discovered this post and mentioned that I should read it, which I take as a good sign.
I’m wondering if there’s some overlap between 1 and 3. Both seem to somewhat resemble where we’re heading at the moment.
Hi Tom. Thanks for the comments; I’m glad the post was helpful.
It would not surprise me to see a hybrid of Type 1 and Type 3 if the organisation has enough maturity and drive to have some Ops folk working directly alongside Devs, while other Ops folk remain further in the background, focused on ‘internal cloud’ or IaaS.
Matthew
I’m confused by your examples. You provide Netflix as an example of an org that is fully-integrated. However, I would argue that Netflix only appears fully-integrated because they are actually the best example of IaaS – being almost fully reliant on AWS for their infrastructure. These types of inconsistencies make question the “moderate” potential effectiveness you’ve assigned to the IaaS pattern. I would argue that IaaS has the highest potential effectiveness of all the options.
Hi Cliff, thanks for commenting.
Having had a few months to reflect on the diagrams, I can see where you’re coming from, and I think I will write a follow-up post to clarify some ideas. To some extent, Type 2 could be a zoomed-in version of Type 3 (Iaas) just without the ‘Infrastructure’ operations part.
The reason I think that IaaS is only *moderate* in effectiveness is for non-EC2 situations, particularly where an organisation runs its own hardware (even as an IaaS setup). When I considered effectiveness, I was thinking about opportunities for product teams to learn about operability and operations by talking to ops people: if infrastructure is provided ‘as a service’, then I think the potential learning opportunities are reduced for many organisations (Netflix is not a ‘normal’ org in my view, so different rules apply).
Etsy might have been a better example for Type2, as they run on physical hardware (not EC2) – in their case, they can align devand ops very closely, largely because they have a single ‘product’ and presumably are in control of all their delivery deadlines (rather than having deadlines set by paying clients).
Matthew
Hi Matthew,
We’ve been reviewing your DevOps topology article (excellent job!) and there’s a question on how the Type 3 should be read when you do DevOps in Public Cloud:
When you do Type 3 DevOps entirely in the Public Cloud (AWS, Azure, Google Cloud etc), you don’t need any Traditional Ops team, right?
I mean, when you’re entirely in the Public Cloud, the “Ops” team in the chart is Amazon or Microsoft, right and there’s not much for a traditional Ops team to do, right?
This may sound like a stupid question, but it may seem like you need an Ops team in Type 3 when you run entirely in the public cloud, and I’m not sure if that’s the case. I’m hoping you could help.
Thanks for your help and for the great work you’ve done here.
Hi Iskren. Thanks for the comments! The important thing about Type 3 is that much of the “Ops” work will be done by a cloud provider BUT that does not mean there is “no Ops”. You will still need a team (probably better called a Platform team) that defines which parts of the public cloud APIs and services to use and how.
In our new book Team Topologies (https://teamtopologies.com/book) we call this approach a Thinnest Viable Platform (TVP), meaning that even if you use a public cloud provider you still need to define what “platform” means for your teams. A simple TVP could just be a wiki page listing the services and APIs that the teams should use. In that case, the “Platform team” might be part-time or quite small, but they still shape and provide a platform through investigating the services and tracking usage, availability, etc.
Hope this helps 🙂
Hi Matthew,
Thanks for the quick response. This helps, indeed.
Doing DevOps in Public Cloud does require a team to define the public cloud architecture in terms of using the right resources.
This team would be more leaning towards Dev and not a traditional Ops type, right?
I mean, they need to work closely with Dev teams and have a sound understanding of the Application in order to design and code the deployment, ideally using Infrastructure-as-code.
My question is rather around the statement in Type 3 suitability:
“Organisations with several different products and services, with a traditional Ops department, or whose applications run entirely in the public cloud.”
This doesn’t necessarily mean that you need “a traditional Ops department” if your apps run entirely in the public cloud, right?
If we put a traditional IaaS guy to do “Ops” work on top of EC2 or Azure VMs (patching, monitoring etc) we end up with the “Rebreaneded SysAdmins” Anti-Type, don’t we?
I don’t see how an IaaS Ops team will contribute if you deploy your VMs/EC2 instances from Pipelines, besides routing tickets to the Public Cloud Vendor or the Dev team.
As others have said, no organizational structure works for everyone and the organization structure is not the destination. In that spirit, it would be valuable to express these patterns more in terms of organization transitions. Type 5 – Temporary DevOps Team is an expression of an expected transition. (When I mentor individuals about organization changes, i remind them that all re-organizations are temporary). When you think this way, Anti-Pattern B can be implemented successfully with the right leadership. I have seen this pattern work when a leader was trusted by both sides and when the team was composed of thought leader from the two sides that had a leadership style that helped others to succeed. When these conditions exist, anti-pattern b can lead to faster change. When the leader is “new” or “unknown” and the team is composes of outsiders, the ANTI- part of the pattern is a certain outcome.
Thanks, John. I plan to write a follow-up post to this one, but until your comment I was unsure of the focus. I’m now certain that a look at *transitions* is the right focus, so thanks for bringing that up.
Matthew
Smartly defined.thanks.
Hi, is there any research or benchmarking done what a healthy ratio of developers-to-ops? Taking into consideration DevOps maturity, system complexity, SaaS native maturity etc.
Best Regards
//Lars Öhlin
Hi Lars. To be honest, these days I think it’s less helpful to think in terms of “Dev” versus “Ops”. I think it’s more healthy to think in terms of engineering with different focus areas. In particular, we’d use the 4 team types from Team Topologies (TT) and ask how many engineers we might see in each type of team or grouping. In TT, we generally say that you should expect the majority of teams to be Stream-aligned (some outside and some inside a Platform), but you may also have a few engineers inside Complicated Subsystem teams and some engineers inside Enabling teams.
The Puppet State of DevOps Report (aka State of Platform Engineering) has some useful global research in this area: https://www.puppet.com/resources/state-of-platform-engineering – also see previous years’ reports.
Hope this helps!