 This article first appeared in Software Development Practice, Issue 1, published by IAP (ISSN 2050-1455)
This article first appeared in Software Development Practice, Issue 1, published by IAP (ISSN 2050-1455)
Abstract
When raising log events in code it can be difficult to choose a severity level (such as Error, Warning, etc.) which will be appropriate for Production; moreover, the severity of an event type may need to be changed after the application has been deployed based on experience of running the application. Different environments (Development (Dev), User Acceptance Testing (UAT), Non-Functional Testing (NFT), Production, etc.) may also require different severity levels for testing purposes. We do not want to recompile an application just to change log severity levels; therefore, the severity level of all events should be configurable for each application or component, and be decoupled from event-raising code, allowing us to tune the severity without recompiling the code.
A simple way to achieve this power and flexibility is to define a set of known event IDs by using a sparse enumeration (enum in C#, Java, and C++), combined with event-ID-to-severity mappings contained in application configuration, allowing the event to be logged with the appropriate configured severity, and for the severity to be changed easily after deployment.
Logging Severity Levels
Almost every contemporary logging framework uses the concept of severity levels to distinguish between log events of different importance: the Apache logging frameworks log4j and log4net (and their stable-mates log4cxx and log4php) have at least FATAL, ERROR, WARN, INFO, and DEBUG; Ruby-on-Rails uses FATAL, ERROR, WARN, INFO, DEBUG, and UNKNOWN; the de facto *nix logger Syslog and its RFC-3164-compliant variants like syslog-ng use Emergency, Alert, Critical, Error, Warning, Notice, Informational, and Debug; and the Windows Event Log uses a minimalist trio of Error, Warning and Information.

These severity levels help to clarify the nature of the logged information; for example, events logged as an Error can be configured to trigger monitoring alerts in tools such as Nagios, Zabbix or SCOM, whereas events logged at the INFO or DEBUG level are perhaps instead left in text log files for later aggregation and analysis by LogStash or Splunk. Depending on how the application is configured, raising events at some severity levels can prevent information being logged in the first place (for example, DEBUG events might be ignored by the logging framework).
How to Choose the Correct Severity Level
When logging an event with frameworks such as log4j and log4net, we typically have to choose the severity at the point of logging, that is, deep in application code. For example, with log4net 2.0, we would write something like:
ILog logger = log4net.LogManager.GetLogger("Logger1");
// ...
logger.Error("Database connection timed out.");
The ILog instance has logging methods Error(), Warning(), Debug() and so on which correspond to a fixed severity level (see sidebar). Notice also that we are coupling our application code to a specific logging framework (here, log4net) which means that this would be awkward to change in the future.
At a high level, the relationship of the application to the event ID, severity, and resulting logs might look like this:
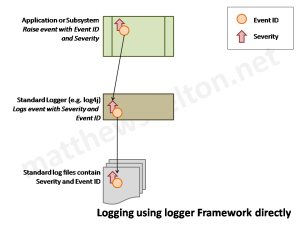
However, our code should ideally not be directly dependent on a particular logging framework, but instead on our own logging API abstraction layer which allows us to change the logging framework implementation later:
// ... Application code ...
CustomLogger.Log("Database connection timed out.", CustomLogLevel.Error);
However, even if we abstract the logging framework from calling code by using our own logging API, we still typically need to specify the severity at the point of logging, because the underlying framework needs to know this value; this is an example of a leaky abstraction.
In this example, the CustomLogger class acts as an API abstraction to hide the use of log4net, but we still need to pass in a log severity level to enable us to log the event:
public enum CustomLogLevel
{
Trace, Debug, Info, Warning, Error, Fatal
}
public class CustomLogger
{
public void Log(string message, CustomLogLevel level)
{
// ...
ILog logger =
log4net.LogManager.GetLogger("CustomLogger");
switch (level)
{
// ...
case CustomLogLevel.Info:
logger.Info(message); break;
case CustomLogLevel.Error:
logger.Error(message); break;
// ...
}
}
}
// ... Application code ...
CustomLogger.Log("Database connection timed out.",
CustomLogLevel.Error);
This abstraction insulates us from the log4net logging framework underneath, but does nothing to enable us to change the logging severity level after deployment, as we still need to specify a logging severity level because the underlying logging framework requires it.
With the API or abstraction layer, the software might be represented like this:

We can see that the specification of the event severity is ‘bubbled up’ to the calling code because it is required by the lower level logging framework, even if we create some kind of wrapper or abstraction.
The Problem with Specifying Severity Levels
The problem here is that the severity given to an event type may need to change after the code is compiled or deployed; the appropriate level may vary in different contexts for the same logical event. For example, an event in a database handler for which a WARNING is appropriate for one component may actually require an ERROR severity in a second, separate component.
Let’s pose a telling question:
How can low-level components or code predict the logging severity level appropriate for the application for each event type?
The answer is, of course, that they cannot and should not. By hard-wiring the severity levels deep within application code, we end up with different effective meanings for ERROR, WARNING, etc. depending on which component is logging; this leads to ‘noise’ in the monitoring system which is bad for human operators. Apache log4net goes some way to solving this by its Level Maps feature (see sidebar) but the configuration required is fairly advanced.
Overriding Appender.append() in Apache log4j
Apache log4j provides the ability to change the severity level of log events by allowing us to override the org.apache.log4j.Appender.append() method. However, this is a fairly ‘heavyweight’ solution requiring additional coding, and does not allow the severity of specific event types to be reconfigured post-deployment.
When deploying applications to different environments (Dev, Test, UAT, Production, etc.) it is often useful to be able to log events with different severities because at each stage of the delivery process we tend to be interested in different things. For instance, an automated acceptance test environment may need to be much more stringent than other environments, and we might know that our Dev environment uses ‘test’ versions of external third-party services which are unfortunately unreliable, so we want to log connection and transaction errors to those services at WARNING or INFO levels rather than ERROR, so that we can more easily distinguish real errors from the noise of failed connections. We certainly do not want to recompile our applications just to deal with flaky test services, so each environment would ideally have its own set of severity levels for given types of events. Normal configuration management good practices should ensure that configuration meant for UAT does not end up in a Production environment.
Logger Repository Level Maps in Apache log4net
Apache log4net is a commonly-used logging framework for the .NET platform, and part of the Apache Logging Services family which includes log4j (for Java), log4php (for PHP), and log4cxx (for C++) – see http://logging.apache.org/. The log4net library has support for Logger Repository Level Maps, which enable per-Assembly and per-application configuration of logging severity levels, so that a call to logger.Error() might be translated at runtime to a log entry with severity set to INFO (for example). This allows system administrators to tune the severity levels for an entire application, component, or assembly, but unfortunately not (yet) for specific event types.
For more details on log4net Level Maps, see http://logging.apache.org/log4net/release/sdk/log4net.Core.Level.html
A Consistent View of Log Events with Event IDs
In addition to an abstraction API to hide the underlying logging framework, each logically separate subsystem should have defined a set of possible events. For a given running program, there is a finite set of N known events which can occur, plus a (potentially larger) set of unknown states or events.
These two sets can this be represented with a set of ‘known event’ IDs or codes, plus a single ‘unknown event’ code which covers all unknown conditions, leading to a maximum of N+1 event IDs:

In my experience, the act of specifying the different event types can itself be a useful exercise, as it forces us to consider the possible states of the application or component.
Real-World Example: search crawler bots
I recently worked on a large transactional web system for a major European financial institution, and in the public-facing web application we were logging one particular ASP.NET web framework event prior to go-live with a level of Warning. However, we discovered after go-live that some web search crawler bots were causing thousands of these warnings every day (as they made HTTP POST requests with incomplete form data); this was causing headaches for the Ops team, as they had to suppress the noisy warnings in the monitoring console, and the extra log entries made it difficult to spot ‘real’ warnings (it would obviously have been difficult to test for this behaviour prior to go-live). Luckily, my team and I had insisted on using a configurable severity level for logged events, and we simply updated the configuration to use a severity of Information for that event instead, without needing to recompile the code; following an application restart, the events were logged at the less noisy severity level, and the Ops team was happy.
Implementing Decoupled Severity Levels
So, how can we defer the decision about the severity of a logged event to a lower-level logging component? How can we effectively decouple the choice of severity level from the act of logging?
We need four things to decouple the event severity from log context:
- A definitive list of possible loggable events, each with a unique ID.
- A configurable mapping between these event IDs and severity levels.
- Low-level ‘mapper’ functionality to funnel the log message, event ID and corresponding severity level through to the logging framework (such as log4j).
- A logging abstraction layer or API above the mapper so we do not need to specify the severity when logging the event in application code.
The mapping itself (2) can simply exist in application configuration and be loaded on application start-up or refreshed on changes, as required. In XML form, the mapping might look like this:
<?xml version="1.0" encoding="utf-8" ?>
<Application.EventMappings>
<Events>
<Event Type="CacheServiceStarted">
<Severity Type="Information"/>
</Event>
<Event Type="PageCachePurged">
<Severity Type="Debug"/>
</Event>
<Event Type="DatabaseConnectionTimeOut">
<Severity Type="Error"/>
</Event>
</Events>
</Application.EventMappings>
The list of events (1) requires more interesting treatment. We need a way to guarantee that each possible event has a unique event ID, and an effective way of achieving this is by the use of sparse enumerations: enumerations with non-sequential integer values. When used with descriptive enumeration (enum) values, we achieve good code readability too. C# and other .NET CLR languages have the best support for this:
public enum EventID
{
// Badly-initialised logging data
NotSet = 0,
// An unrecognised event has occurred
UnexpectedError = 1000,
ApplicationStarted = 1001,
ApplicationShutdownNoticeReceived = 1002,
PageGenerationStarted = 2000,
PageGenerationCompleted = 2001,
PageGenerationHTMLFragmentCacheHit = 2002,
PageGenerationHTMLFragmentCacheMiss = 2003,
MessageQueued = 3000,
MessagePeeked = 3001,
MessagePopped = 3002,
MessageMissing = 3003,
MessageCopied = 3004,
// ...
}
Java needs additional (slightly ugly) code to translate the integer value back to the enum values, but the principle is the same:
public enum EventID
{
// Badly-initialised logging data
NOTSET (0),
// An unrecognised event has occurred
UNEXPECTEDERROR (1000),
APPLICATIONSTARTED (1001),
APPLICATIONSHUTDOWNNOTICERECEIVED (1002),
PAGEGENERATIONSTARTED (2000),
PAGEGENERATIONCOMPLETED (2001),
PAGEGENERATIONHTMLFRAGMENTCACHEHIT (2002),
PAGEGENERATIONHTMLFRAGMENTCACHEMISS (2003),
MESSAGEQUEUED (3000),
MESSAGEPEEKED (3001),
MESSAGEPOPPED (3002),
MESSAGEMISSING (3003),
MESSAGECOPIED (3004);
// ...
// Reverse look-up logic not shown
}
The low-level mapper (3) which selects an appropriate logger to use for logging the event is essentially a switch statement, and trivial to implement. The abstraction layer or API (4) sits above the low-level mapper and reads the event ID-to-severity mappings, allowing us to log distinct events using the event IDs but without specifying the severity, like this:
public class DecoupledLogger
{
public static void Log(EventID eventID, string message)
{
// ...
ILog logger =
log4net.LogManager.GetLogger("DecoupledLogger");
CustomLogLevel level = GetLevelForEventID(eventID);
switch (level)
{
// ...
case CustomLogLevel.Info:
logger.Info(message); break;
case CustomLogLevel.Error:
logger.Error(message); break;
// ...
}
}
private static CustomLogLevel
GetLevelForEventID(EventID eventID)
{
// ...
}
}
We are now able to hide the severity detail behind the API, allowing us to make a much more elegant call when logging:
DecoupledLogger.Log(EventID.MessageQueued, "message details");
Compare this to the earlier examples where the caller was forced to supply some kind of severity at the point of logging:
CustomLogger.Log("Database connection timed out.", CustomLogLevel.Error);
Not only do we gain the ability to defer the decision on severity to a lower layer, but we also end up with more readable, more self-documenting code, as we have had to choose from a finite, defined set of event IDs to describe the condition we are logging.
Useful Properties of Sparse Enums for Event IDs
Enums are useful for holding the event IDs for several reasons:
- The compiler will report an error if two enum entries are assigned the same integer value, making for a very robust, compile-time check that the ID values are unique.
- Compilation will also fail if an expected event enum value is not defined in the version of the enum event ID package being used.
- Being able to use non-contiguous ‘blocks’ of event IDs is useful because we can assign ranges of IDs to different kinds of events, gaining some human-readable benefits if we ever see the integer values of the enum.
- We can rely on a given enum value and its corresponding integer ID being tied to a specific event type or condition (that is, the event ID has a fixed semantic value). For example, using grep or tools like LogStash we can search across logs for occurrences of the event ‘MessagePeeked’ or ‘3001’ and know that these represent the same ‘event concept’.
- The source code becomes the definitive reference for the meaning of event IDs, and there is no need to keep track of the values and meanings separately.
There are some important consequences of being able to rely on the integer event ID to identify a given type of event. The meaning of a given enum value and event ID is immutable: once an event ID has been used from the ‘pool’ of possible IDs, it cannot be re-used for any other meaning. New IDs can be added to the enum, but old event IDs cannot be re-used for new events, unless a refactoring across the whole dependent code base occurs (but that still leaves ambiguity when reviewing older code); in practice, it makes sense to keep the old event IDs around for future use when analysing metrics.
Logging With Decoupled Severity
Let’s review our ‘shopping list’ of requirements for allowing the tuning of logging levels without recompiling an application:
- A list of loggable events, with unique IDs
- A configurable mapping between event IDs and severity levels
- Low-level ‘mapper’ functionality to funnel the log details through to the logging framework
- A logging abstraction layer above the mapper
The software layers for logging then appear something like this:

Here we can see that the application needs to know only about the event IDs, not about the severity levels associated with those events. The severity levels are held in configuration, and the association of event ID to severity level is performed by a Mapper layer, hidden behind the logger abstraction API. The Mapper layer is then responsible for using standard logging frameworks like log4net and log4j to write the log message to the correct log listener.
The algorithms for using mapped severity levels are simple:
On application startup (or other config refresh):
- Inject the event ID / severity mappings into the Mapper as a collection
On logging an event:
- Look up the event ID in the mapping configuration and determine the severity
- Find an appropriate logger for that severity
- Log the event using the standard logging framework
All this adds minimal overhead to the logging activity, as the only real additional work is the collection lookup inside the Mapper; as we’re using unique integers as keys, the hashtable lookup is rapid, and should not appreciably delay the logging operation.
The need to define all expected events with a central logger component of course implies some coupling; each independent (sub-)system might need its own event ID set. The (sub-)system will thus be self-consistent in terms of severity levels and event IDs.
Further Considerations
Aggregating separate log file entries
Logging frameworks, such as log4j / log4net, are often set up so that a given logger instance will listen for alerts of one particular severity only. We therefore need an intermediate logger mediator or Mapper, which can then pick the correct logger to use, based on the severity. One downside of splitting log events by severity is that contextually related events are logged to different files, so piecing back together a series of related messages can be tricky; use of log aggregation tools like LogStash and Splunk or remote log servers such as syslog/syslog-ng can help here.
Syslog Facility Codes
For software using Syslog, we can extend the event-ID-to-severity mapping to map event IDs to the 24 Syslog ‘Facility’ codes confirmed in the latest Syslog specification (RFC 5424), removing the need to leak the concept of Facility through to higher layers. The mappings can be held in application configuration along with the mappings between event ID and severity.
Windows Event Log
When logging events to the Windows Event Log, it’s worth bearing in mind that the Event ID field of the Windows Event Log is treated by many Windows tools a 16-bit integer, limiting the number of discrete event IDs to around 32,000 per Event Source. However, this should still provide plenty of scope for most systems; if necessary, use a separate Event Source to gain additional event IDs.
SCOM Management Packs
Using Microsoft System Center Operation Manager (SCOM) for managing alerts and events, we will need to produce a ‘management pack’ for the events of interest in Windows event logs. The simplest way to achieve this is with an XSL transform on the XML configuration defining the event-to-severity mappings for a given environment; in this way, the generation of management packs can be independent of the generation of binaries, and tailored to a particular environment if required. The mapping configuration can be decorated with descriptions and other attributes useful for the event management console.
Configuration Management
Placing the event-ID-to-severity mappings in application configuration means the usual care should be taken to avoid overwriting (say) Production settings with those for a Dev environment. Normal configuration management best practice should be sufficient here.
Extending the Mappings with Care
Perhaps we might further extend the event ID mapping by selecting the severity (or facility) based on some simple rules, such as time of day, although care would be needed to ensure that the logging substrate was kept simple and rapid: calls to databases or other external components during logging would obviously be unwise.
Summary
The severity of a logged event often depends on context, and may need to be changed after deployment. Furthermore, specifying the severity of log events at the point of logging breaks encapsulation and results in variant meanings for ERROR, WARNING, etc. for different subsystems, causing noise in operations monitoring and metrics.
The combination of a defined set of expected event types using a sparse enum for event IDs, a mapping of these event IDs to severity contained in application configuration, and a corresponding logger abstraction/API allows us to decouple the severity level of event types from the application/component code where the event is logged.
This provides a way to adjust the severity mapped to event types after the code is deployed to Production – without recompiling the code – by editing application configuration, and better encapsulates the underlying logging operations from higher level code.
As computer scientist David Wheeler once remarked, “All problems in computer science can be solved by another level of indirection… except for the problem of too many layers of indirection.”
Sample code in C# is available at https://github.com/matthewskelton/TuningLoggingLevels
Thanks to John Catlin and Attila Sztupak for comments and suggestions
What would you see as the downside of the other approach where I “invert the order of operations”. So for instance I have events which are logged and ultimately dispatched to syslog. From there they can be processed by a component like logstash or graylog2 and the rules can be applied using a tool like http://www.jboss.org/drools/
That seems a bit better to me as I don’t need to know the event ahead of time or maintain the enum. I can then express the mapping between event serverity in a file alterable at runtime. This makes it play better with legacy systems or even have different severities of the same message for different operations groups.
Nice blog in anycase lots of tremendous info here.
Barrett, I’ve been thinking further about all this recently. One definite benefit of attempting to define all possible events “up front” is that it can help to make the software more operable. Specifically, if the software team can demonstrate that their software is going to be operable by supplying a draft operation manual/run book to the operations team (including details of all the events), the operations team has a much better chance of catching error conditions swifty and responding to P1 incidents better. See http://softwareoperability.wordpress.com/2013/02/02/focus-on-application-support-and-maintainability-to-produce-operable-software/ for some more thoughts on that approach.
Ultimately, as long as logged events can be correlated to discrete application states, and the operations team can react to these messages rapidly and appropiately, the exact mechanism is moot.
Matthew
Thanks, Barrett. You raise in interesting point. I’m not familiar with Drools, but I like Logstash (I’m in the process of rolling it out for our build & test farm) and Syslog is a given. I think that purpose or focus of Logstash/Graylog2/Syslog are somewhat different to that of determining logging levels; in fact, if you combined my configuration approach with Logstash, you’d likely get even better use from your logs, as you;d be able to grep for a specific event ID – *bam*.
With the “log everything and let Logstash/Syslog/etc. decide what to do with it” approach, I think you might run into what Steve Freeman (@sf105) calls Logorrhea (see http://softwarefromnorth.blogspot.co.uk/2011/04/33rd-degree-in-krakow.html –> “Steve Freeman – Fractal TDD: Using tests to drive system design”, but the normal definition works too: http://en.wikipedia.org/wiki/Logorrhoea). By this, I mean that you might not want to fill your Logstash with 3TB of DEBUG messages which a developer left in for some reason – using configuration to switch these off, or indeed select only the interesting messages, would make for a more useful log database.
Do you tag your log messages with unique IDs, or do you rely on string pattern matching (or some other matching) in order to filter/group/prioritize log messages? I’d be interested to read about your approach in more detail.
Hi Matthew!
Great post, I really liked the approach to logging. So much in fact, that I built a small wrapper around log4net to implement what you describe. You can read my reasoning on my post http://open.bekk.no/better-logging-using-enumeration and find the implementation at https://github.com/thomassvensen/EnumeratedLogger. I would really appreciate if you had time to take a look at it and evaluate whether you think the approach makes sense.
Thank you
Thomas