Call JavaScript from C# code, passing parameters and returning results.
I came across a need to call JavaScript methods on HTML code inside a web page from a C# WinForms application. How could that language gap be bridged?
It turns out that Type.InvokeMember() does the trick when using a [Internet Explorer] WebBrowser control to load a web page.
using mshtml;
...
private AxSHDocVw.AxWebBrowser axWebBrowser1;
...
///
/// Retrieves a reference to the HTML element containing a DIV. /// JavaScript methods are implemented on this element itself. ///
/// A reference to the HTML element holding the JavaScript methods
private HTMLDivElementClass GetContainer()
{
HTMLDivElementClass container = null;
IHTMLDocument2 doc = axWebBrowser1.Document as IHTMLDocument2;
if (null != doc)
{
foreach (IHTMLElement element in doc.all)
{
if (element.id == "My_Container")
{
container = element as HTMLDivElementClass;
break;
}
}
}
return container;
}
///
/// Gets the text from the container ///
/// A string containing the text of the container
private string GetText()
{
string result = null;
HTMLDivElementClass div = GetContainer();
if (null != div)
{
Type type = div.GetType();
result = (string) type.InvokeMember(
"GetText",
BindingFlags.InvokeMethod,
null,
div,
null);
}
return result;
}
The HTML page loaded in the WebBrowser control has a DIV element with an id of “My_Container”, attached to which is a method called GetText(), which returns some arbitrary text.
Having acquired a reference to the DIV on which the JavaScript method is declared (using GetContainer()), the JavaScript method is called using the InvokeMember() method of the Type class instance; the return value is cast to a string.
Discussion
There is every reason why this should NOT work, but the implementers of the WebBrowser control decided that JavaScript methods living within the DOM should be accessible as first class object members at runtime (in this case, via IDispatch). Nice!
Result
C# code can call arbitrary JavaScript within an HTML page! The only limitation is that the return types of the JavaScript methods can be only simple types (even DateTime is too complex).
I have some experience with using DotNetNuke as a CMS. It’s free, open-source, and has pretty good engineering. There are plenty of add-on modules available from sites like Snowcovered. Some of the UI elements are irritating: like a lot of early ASP.NET sites, there are too many postbacks, but it works well in general, and is easy to manage.
Community Server is targetted at a different market, and is ready-made for a typical portal site, with blogs, file downloads, forums etc.; whereas DNN is more like a toolbox, Community Server is one of those 5-in-1 screwdriver/drill combos. The asp.net site now runs Community Server, not surprising, since both are Microsoft-driven.
CMSs like PHP-Nuke are hopelessly out of date and riddled with bugs. In 2006 there is no excuse for having anySQL Injection vulns in web applications. Just do not execute raw SQL from the code: use Stored Procedures and parameters!
I spent part of today scratching my head and dredging up long-forgotten details of the .Net Framework and C# over at BrainBench.com – to my relief, I didn’t disgrace myself: a test score average of 4.25 puts me in good stead for my forthcoming MCP exam later in June.
The following items can be serialized using the XmLSerializer class.
Public read/write properties and fields of public classes.
Classes that implement ICollection or IEnumerable. (Note that only collections are serialized, not public properties.)
XmlElement objects.
XmlNode objects.
DataSet objects.
Forcing the compiler to check for CLS-compliancy – [CLSCompliant(true)]
A whole bunch of stuff on Code Access Security – though the basic idea is quite simple: establish security requirements at compile time, and DEMAND that running code has those permissions before allowing execution (as opposed to running as far as possible with the current credentials/rights)
Some details on XSD.exe: workarounds, and an improved version – I discovered that even then VS2005 version of XSD.exe has some serious bugs, such as eating memory when presented with a multi-table SP-based dataset.
Finally (as it were) we have Non-deterministic finalization, and destructors/Dispose() – often safely ignored in simpler code, but can lead to Bad Things if abused in enterprise applications
Microsoft Application Blocks form a collection of ready-built ‘clumps’ of code which solve common problems such as security management, data access, logging, etc. They are the tangible result of the Microsoft Patterns and Practices advice: all of it sound and solid.
…you don’t have to worry about the tedious details required to return a DataReader or write an exception to the System Log. This allows us to concentrate on the business logic in our applications.
I have written too many logging frameworks in the past: it’s boring above all else. I just want to log exceptions in a thread-safe manner, with a unique ID.which I can display to the user if necessary. If someone (i.e MS) has already written code to do (most of) this, then fine – I’ll use it.
The Security block is particularly useful for ASP.NET 1.1, where security and profile management is not as simple as in version 2.0. All that boring stuff about storing Role information in cookies? Solved! Better still, any security holes will be fixed by MS. Again, more time to concentraste on business logic.
Design Guidelines for Class Library Developers
The Application Blocks tie in nicely with a set of guidelines from MS on class library development. They include advice on:
array usage
exposure to COM
casting
threading
and several other subjects. This is basically just a gloop of Common Sense, but well worth a read.
MBR BootFX Application Framework
An alternative to the MS Application Blocks comes from Matt Baxter-Reynolds (he of DotNet247) in the form of BootFX:
The MBR BootFX Application Framework is a best-of-breed application
framework that we offer to all our clients who engage us to develop
software applications or software components for them. It’s designed
to give us a “leg up” on new projects by providing a tried and tested
code base for common software development activities.
There are lots of goodies there, including Object Relational Mapping (ORM), and support for SQL Server, Oracle, and MySQL databases. To top it all, it’s open source, via the Mozilla Public Licence 1.1. I met Matt 18 months or so back at a seminar run by Iridium; very personable guy.
The Delegate type is a powerful feature of C#. This article introduces delegates, and shows how they can be used to solve a common problem: ensuring that a series of database updates occur as a single operation by use of a transaction. The solution presented is flexible and minimises duplication of code.
Transactions
Transactions are essential for maintaining data integrity within comp uter systems; they seek to guarantee that logically dependent data are amended together in (effectively) a single operation. If an error occurs during that operation, the entire operation fails, and no changes are persisted. Indeed, the ACID (1) properties of a database rely heavily on correctly implemented transactions[i].
However, the application developer should not be forced to memorise the details of transaction-handling code in order to perform ‘ACID-ic’ data updates: transaction code should be transparent, and not interfere with core application logic.
The ‘boiler-plate’ transaction code (i.e. that which is generic) would best be hidden behind a programming interface that feels ‘natural’; ideally, we would have just a single point in the code for handling transactions. With the complex details of transactions hidden, programmers are free to concentrate on application logic.
We need a solution which:
Minimises proliferation of transaction code.
Hides the details of transaction code
Allows data update code to be defined separately from transaction code.
Potential Solutions
The programmatic nature of transactions can be summarised as:
BEGIN transaction
EXECUTE updates in context of transaction
COMMIT/ROLLBACK transaction depending on result of EXECUTE.
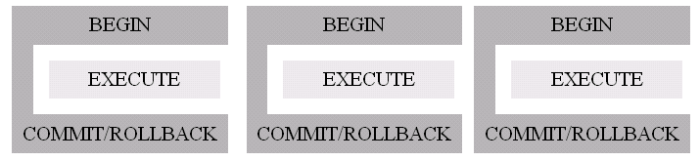
The BEGIN and COMMIT/ROLLBACK actions represent the ‘boiler-plate’ code, whereas EXECUTE is dependent on specific data update requirements. Figure 1 shows this relationship.
Figure 1 – Generalised transaction logic. The EXECUTE stage is logically separate from the BEGIN and COMMIT/ROLLBACK stages.
Here are some possible schemes for using transactions:
Wrap BEGIN and COMMIT/ROLLBACK around every EXECUTE operation (Figure 2). This provides flexibility in the definition of EXECUTE, but at the expense of gratuitous code duplication, with associated maintainability problems: if changes are needed to the code for BEGIN or COMMIT/ROLLBACK, those changes must be propagated throughout the application code.
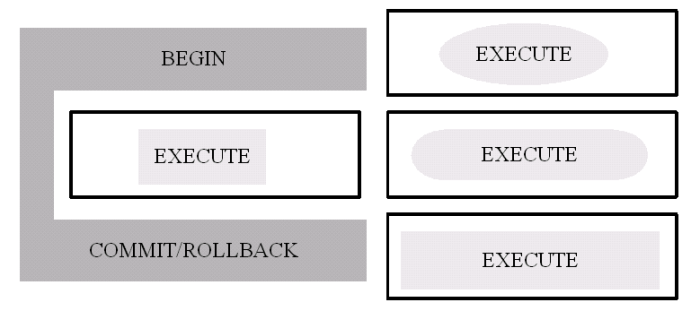
Derive a group of data update classes from a common base class. Place the BEGIN and COMMIT/ROLLBACK code within a method on the base class, and have it call an overridden virtual method on derived classes to perform the EXECUTE logic. The limitation of this scheme is that a type hierarchy is imposed on data update code, which may not fit with existing class models, and which will likely lead to ‘brittle’ code and inflexibility for programmers. This is shown in Figure 3 – the EXECUTE methods are restricted in functionality by being derived from the same base class.
Use the Automatic Transactions feature supported by .NET (12). This makes use of COM+/MTS technologies, and requires some specific code and application modifications that may not be applicable or suitable in many cases, and does not provide precise control over the transaction used for a given method.
Figure 2 – Transaction code explicitly surrounding each data update.Figure 3 – A base class handles the BEGIN and COMMIT/ROLLBACK logic, with overridden EXECUTE methods containing data update logic. Data update methods are limited to a single class hierarchy.
Sidenote: Transactions and DataSets in C#
Transactions in C# (4, 7) are simplified by use of the Framework Class Library (FCL) System.Data.IDbTransaction interface, which provides Commit() and Rollback() methods, and a Connection property, allowing the transaction to take place in the context of a particular database connection. This interface allows us to use the same database update logic with different database types and transaction models.
A Solution: C# Delegates
The ECMA specification (4) for C# introduces the delegate type thus:
Delegates enable scenarios that some other languages have addressed with function pointers. However, unlike function pointers, delegates are object-oriented and type-safe.[ii]
A delegate is declared as follows:
public delegate void SomeDelegate(int i);
The delegate SomeDelegate expects a single int parameter and returns no value. Note the keyword delegate. The delegate is invoked as follows:
public class SomeClass
{
// ...
// Signature matches that of delegate
public void SomeMethod(int i) { /* do something here */ }
// ...
}
public class AnotherClass
{
public void CallDelegate(int i)
{
SomeClass c = new SomeClass();
// Wrap the method as a delegate
SomeDelegate d = new SomeDelegate(c.SomeMethod);
// Invoke the delegate
d(i);
}
}
The delegate acts a typed ‘wrapper’ around another method. Following instantiation, the delegate object is ‘free’ of the class in which its wrapped method is defined; the delegate can be treated as (and in fact is) a first-class object in its own right. For example, the delegate can be stored in a container or list of some sort for later processing, if required. So, delegates can be considered as akin to type-safe function pointers (or somewhat analogous to function objects in C++ and Python).
By placing all data update code inside delegate methods, it is possible to trigger all data updates in the same generic way: namely, by invoking the appropriate delegates. The parameters expected by one update method are identical to (or compatible with) those expected by all other update methods. We can thus guarantee that every delegate-based update method has access to the required IDbTransaction reference to use during data updates. Referring back to Figure 1 and the three stages of a transactional data update, we now have a way to link any EXECUTE step (contained within a delegate) to the transaction associated with our BEGIN and COMMIT/ROLLBACK logic. See Figure 4:
Figure 4 – Transactions using Delegates. The delegate EXECUTE methods can be invoked in a generic way (outer box) but may belong to disparate classes and contain very different logic.
However, C# delegates sport another feature which is particularly useful in the context of this article[iii]: they have ‘multi-cast’ abilities. Delegates of the same type can be ‘combined’ or concatenated (using the overloaded operator +=), producing a new delegate object which will – when invoked – call each of the original delegates in turn.
This multi-cast feature can be used to chain together a sequence of data update calls, without the need explicitly to manage the group of delegates in the chain. For example, data updates might be queued on a background thread, and then submitted together as a batch. The code invoking the multi-cast delegate need not know how many individual delegates will be invoked; the invoked delegate handles this automatically.
Delegates: Recapitulation
Delegates will allow us to place our database update code in any class we choose, providing we arrange for the method signature of the update methods to match that of a particular delegate. We can pass into the delegate method the IDbTransaction reference for use during data update.
A Working Example
The following code demonstrates the ideas presented so far in working code.
First we declare our delegate which expects two parameters: sender and args (details follow later).
public delegate void TransactionedOperationDelegate(TransactionWrapper sender, TransactionArgs args);
Next we declare a lightweight class to represent a database update operation:
public abstract class TransactionedOperation
{
public TransactionedOperationDelegate Execute;
}
We must derive sub-classes from this class, as it is marked abstract, and therefore not instantiable. It holds a delegate reference in its Execute field. We will return to this shortly.
Referring to the basic transaction model (see Potential Solutions, above; Figure 1), we can map out the method required to implement the BEGIN and COMMIT/ROLLBACK logic.[iv] The various data update operations passed to this method should be treated as a single, atomic operation:
// Make all operations into one atomic operation
public void MakeAtomic(TransactionedOperation[] operations)
{
// Connection is set elsewhere
this.Connection.Open();
try
{
// BEGIN
using (IDbTransaction transaction = this.Connection.BeginTransaction())
{
try
{
/// Prepare, then call each operation
/// Any exceptions will abort the transaction
///
foreach (TransactionedOperation operation in operations)
{
// EXECUTE
// Invoke the delegate here! operation.Execute(...) // ...
}
// COMMIT...
transaction.Commit();
}
catch (Exception exception)
{
// ... or ROLLBACK
transaction.Rollback();
// TODO: Log the exception here
// Re-throw exception
throw;
}
}
}
finally
{
this.Connection.Close();
}
}
The code as shown implements the BEGIN and COMMIT/ROLLBACK stages of the transaction logic. What is missing is the EXECUTE stage; that is, the invocation of the data update delegate contained in each TransactionedOperation in the operations array. What sort of parameters should we pass to the delegate? We clearly cannot make any sensible generalised assertions about the kind of parameters that might be needed by any given data update method. After all, one of the goals of using delegates is to allow data update code to reside in any arbitrary class; locking down the parameters would negate that flexibility.
The solution is to allow calling code to ‘hook on’ parameters to the TransactionedOperation parameter, by deriving a sub-class (as mentioned above), and defining new fields[v] to store the required parameters. For example:
public class CustomTransactionedOperation : TransactionedOperation
{
// hook arbitrary data...
public CustomTransactionedOperation (CustomDataSet dataSet)
{
this.Example = dataSet.ExampleData;
}
public readonly string Example;
}
A sub-class CustomTransactionedOperation is derived from the base class TransactionedOperation. A delegate method can now access the Example field of the operation parameter.
Remember that the delegate method takes two parameters: a reference to the TransactionWrapper calling the delegate (the ubiquitous ‘sender’), and a parameter of type TransactionArgs. We use this second parameter to pass essential information to the delegate method:
public class TransactionArgs : EventArgs // for convenience
{
public TransactionArgs(IDbConnection connection, IDbTransaction transaction, TransactionedOperation operation)
{
this.Connection = connection;
this.Transaction = transaction;
this.Operation = operation;
}
public readonly IDbConnection Connection;
public readonly IDbTransaction Transaction;
public readonly TransactionedOperation Operation;
}
The CustomTransactionedOperation (with its custom data fields) can be attached to the TransactionArgs parameter, thereby allowing arbitrary information to be passed to the delegate method.
Our code for invoking an operation delegate therefore looks like this:
// Connection is an IDbConnection reference
// transaction is an IDbTransaction reference
// operation is a TransactionedOperation reference
//
TransactionArgs args = new TransactionArgs(Connection, transaction, operation);
operation.Execute(this, args);
It might seem slightly strange that we use the operation parameter twice (once to allow us to call the delegate, and a second time to pass custom parameters to the delegate inside args): this is largely for convenience, although also allows for flexibility in the management of update operations.
All that is left now is to prepare the TransactionedOperation and use the TransactionWrapper class to make the data update operation(s) atomic:
// Some arbitrary update code, somewhere...
public void UpdateCustomDetails(CustomDataSet dataSet)
{
// Connect here to a SQL Server database – could change
IDbConnection connection = new System.Data.SqlClient.SqlConnection( /* connection string */ );
TransactionWrapper transactionWrapper = new TransactionWrapper(connection);
// Hook the data onto the operation parameters
CustomDataUpdate customDataUpdate = new CustomDataUpdate();
CustomTransactionedOperation operation = new CustomTransactionedOperation(dataSet);
operation.Execute += new TransactionedOperationDelegate(customDataUpdate.UpdateData);
/* chain another delegate here if required:
operation.Execute += new TransactionedOperationDelegate(SomeOtherDelegateMethod);
*/
// wrap in transaction
transactionWrapper.MakeAtomic(operation);
}
The delegate used here is the UpdateData() method of a CustomDataUpdate instance. This is the method that will make use of the IDbTransaction transaction to perform atomic updates. Other update methods that expect the same dataset[vi] can be chained on to the first delegate (shown in comments). Each delegate in the multi-cast chain will receive the same arguments. The UpdateData() method could look like this:
public class CustomDataUpdate
{
// The delegate method
public void UpdateData(TransactionWrapper sender, TransactionArgs args)
{
// Expect special operation type
CustomTransactionedOperation operation = args.Operation as CustomTransactionedOperation;
SqlCommand sqlCommand = new SqlCommand();
sqlCommand.Transaction = args.Transaction as System.Data.SqlClient.SqlTransaction;
sqlCommand.Connection = args.Connection as System.Data.SqlClient.SqlConnection;
// Use custom params from operation object
sqlCommand.CommandText = operation.Example; // etc.
sqlCommand.ExecuteNonQuery();
}
}
Clearly, a production system would employ somewhat more sophisticated logic, but the principle remains!
Roundup
The code presented above achieves the three goals set out at the beginning of this article: there is no proliferation of transaction code (only a single method, TransactionWrapper.MakeAtomic() holds such code[vii]); data update methods need only use the IDbTransaction reference when calling into the database (no other details are needed); and data update methods can be defined in arbitrary locations, and can require arbitrary data, and all participate in transactions in the same way. See Figure 4.
The scheme provides additional benefits, such as the ability to log all details of a transaction at a single point (in the TransactionWrapper).
Finally, the scheme implements a modified version of the Command Pattern (1) with the operation.Execute() method (3) functionality, and the TransactionWrapper is arguably an implementation of the Façade Pattern (2).
Observations and Notes
In this scheme all database updates take place synchronously within the same IDbConnection context. Use of a single connection is normally essential for transactions (although MS SQL Server allows sharing of transaction space between connections via a special Stored Procedure sp_bindsession – see (10)). Delegates are processed (and data updated) in order of submission to the TransactionWrapper.MakeAtomic() method.
C# delegates also support asynchronous execution, but this scenario has not been tested with the scheme presented here. If the ordering of data updates is not important, then it is possible that asynchronous delegate execution could be made to work with this code, but mixing asynchronous calls with transactions could lead to problems: transactions typically lock (part of) a database during execution, and long-running transactional asynchronous method calls could therefore cause performance bottlenecks.
Any method that performs data update using the technique presented here must use the provided IDbTransaction interface. A deadlock condition is likely to ensue if an application mixes transactional database requests with non-transactional requests. Enforcing this requirement is probably largely down to good practice.
The scheme is not designed to support Distributed Transactions, although could in principle be modified for such a purpose, if a suitable implementation of the IDbTransaction interface were available.
It might be useful to consider providing event notifications at certain stages of the transaction, such as TransactionStarted, TransactionCommitted, TransactionAborted, etc. This would allow listeners to register for notification of these events, probably in the context of the submission to the TransactionWrapper of a group of transactional operations.
The code demonstrated here has been tested only with the Microsoft version of C#, running under the .NET Platform (versions 1.0 and 1.1) (9), but should work with little or no modification under alternative C# implementations, such as Mono (8).
Summary
This article introduced the C# Delegate type, and showed how it can be used to coordinate and simplify the management of transactional database updates. We have seen a coding scheme using Delegates which keeps tight control of the transaction logic, while also allowing a good deal of flexibility in the definition and location of database update code.
[i] Here, ‘transaction’ generally refers to a one-phase operation between a single database and a single application. Distributed Transactions (between multiple data sources and/or applications) are out of the scope of this discussion.
[ii] The ECMA spec also notes: The closest equivalent of a delegate in C or C++ is a function pointer, but whereas a function pointer can only reference static functions, a delegate can reference both static and instance methods. In the latter case, the delegate stores not only a reference to the method’s entry point, but also a reference to the object instance on which to invoke the method.
[iii] Delegates are also used to implement anonymous methods in C# 2.0 (13), but that subject is beyond the scope of this article.
[iv] Error handling omitted for brevity
[v] Read-only fields are used instead of the ‘better practice’ properties purely to minimise code bloat.
[vi] Although not central to this discussion, it is worth mentioning the FCL System.Data.DataSet class. An object of this class is an in-memory cache of data retrieved from a database, and greatly simplifies data retrieval and update operations. Strongly-typed datasets can be used, whose class definitions are created from XML Schema (11), allowing compile-type type-checking of dataset operations, and access to tables and columns by name, instead of collections and indices.
[vii] In some respects, the plumbing required for transactions is akin to some of the problems addressed by Aspect-Oriented Programming (6), although such issues are beyond the scope of this article.
References
Design Patterns: Elements of Reusable Object-Oriented Software – E. Gamma, R. Helm, R. Johnson, J. Vlissides: , Addison-Wesley, Reading, 1995. ISBN 0-201-63361-2